Сравнение 5 конфигураций RAG по судебной практике: почему я вам ничего не расскажу о результатах
Я задумала это исследование ещё в начале 2026 года, больше 10 человек помогли мне с данными для него, я очень долго разрабатывала дизайн исследования и, собственно, делала его — на всё ушло почти 3 месяца. Но поделиться результатами я не могу, и в этом посте расскажу, почему так вышло.

Если вы пересекаетесь со мной в каких-то профильных чатах, вы могли знать о том, что я планировала наконец узнать всю правду, обсчитав качество retrieval для разных способов организации RAG по судебной практике. У меня уже давно были гипотезы на этот счёт, очень хотелось проверить их, а также испытать в деле некогда вычитанный SAC-метод.
План был достаточно амбициозный, хотелось сделать с академическим качеством, и, может, даже подать результаты на какой-нибудь ML-воркшоп, так как прикладной новизны здесь прорва: можно считать, что научных работ по RAG на российских юридических документах просто не существует.
С января я стала краудсорсить данные, предварительно посоветовавшись с нейронками: вроде как на корпусе из 200 кейсов и 50 вопросов к ним можно было бы строить эксперимент и даже экстраполировать выводы. Получилось даже чуть больше: 218 судебных актов, 70 вопросов с размеченными ответами. Все 5 RAGов я сделала, все эксперименты прогнала, обсчитала и построила кучу графиков. Но в результатах что-то бросилось в глаза... и на методологическом ревью выяснилось, что из многочисленных заявленных исследовательских вопросов на моих данных осмысленно и статистически значимо проверяются где-то полтора. И даже тот единственный формально «доказанный» результат достигнут методологически неверно.
Про это будет пост: он может быть вам интересен, если вы любите читать о чужих факапах, вам интересна статистика и валидация выводов в научных работах (на очень простом уровне, обещаю), или вы делаете legal RAG в нашем тесном русскоязычном кружочке. Будет о проблеме размера выборки и проблеме дедупликации чанков, которую, кажется, могут недооценивать RAGостроители баз российской судебной практики.
Что я сравнивала
Если коротко, то следующие методы подготовки данных для RAG-базы:
- Summary-Only — на который была главная ставка. То есть на метод с предварительной генерацией структурированных LLM-саммари каждого судебного акта (один документ = один эмбеддинг);
- 2 типа «классики» в лице наивного (или плоского) чанкинга сырых текстов. Первый с помощью managed-платформы Google File Search, второй — самосборный пайплайн с cross-encoder-реранкером;
- Простой советский поиск по ключевым словам, BM25, как лексический baseline;
- SAC-метод (Summary-Augmented Chunking — чанки с префиксом-саммари дела), про который я подробно писала в обзоре про Document-Level Retrieval Mismatch.
Моя давняя гипотеза такова: российские судебные акты (и другие правоприменительные акты) — это сплошной текст без структурной разметки, обильно засорённый процессуальными формулировками и дословным цитированием норм. Саммари должно убирать шум и оставлять существенное. Именно так я делала RAG по практике ФАС, и результаты в целом очень хорошие (хоть и без замеров). Я ожидала, что Summary-Only окажется уверенным лидером по всем параметрам.
Технические детали методов — для интересующихся
- Метод 1. Naive Chunking через Google File Search. Managed-решение: загружаешь тексты, Google сам их чанкует (512 токенов, overlap 50) и индексирует. Поиск через встроенный векторный индекс, на запросах —
top_k=20,temperature=0, минимальный thinking. - Метод 2. Summary-Only. Для каждого дела генерируется структурированное саммари (предмет спора → обстоятельства → доводы сторон → позиция суда → применимые нормы → исход) длиной ~1000–1500 токенов, потом этот текст векторизуется. Один документ = один эмбеддинг
gemini-embedding-001размерности 3072. - Метод 3. SAC. Для каждого дела генерируется короткая аннотация (~150–200 символов), которая приклеивается префиксом к каждому чанку этого дела. Дальше — обычный векторный поиск по чанкам с префиксом.
- Метод 4. BM25. Поиск по ключевым словам, но сначала запрос и каждый документ приводятся к словарной форме (это называется лемматизацией), чтобы, например, «договоров» и «договору» матчились на «договор» — относимся с почтением к русской морфологии. Дальше — стандартный алгоритм BM25 с дефолтными параметрами, который существует с 80-х и который уже сто раз похоронили.
- Метод 5. Vector Search + Reranking. Стадия 1 — векторный поиск по сырым чанкам (top-20), стадия 2 — cross-encoder
bge-reranker-v2-m3пересортирует эти 20 чанков. Позже добавила контрольный прогон с другой моделью реранкера —mmarco-mMiniLMv2, — чтобы проверить, не артефакт ли слабый эффект от конкретной модели.
Плюс виртуальная серия method5_stage1 — выдача стадии 1 метода 5 до реранкинга. Нужна была для отделения двух эффектов: «что даёт реранкер» и «managed vs custom на одной embedding-модели» (то есть Google File Search против самосборного пайплайна).
Всё считала на 70 тестовых вопросах с эталонной разметкой (ground truth), собранной десятью контрибьюторами. За что им, конечно, огромное человеческое спасибо — о них ещё скажу отдельно.
Проблема номер один: 70 вопросов — это скромно для большинства сравнений, которые хотелось делать
Что такое статистическая значимость и базовые инструменты её подтверждения
Сначала познавательная пятиминутка с базовым техническим минимумом, без которого дальше будет непонятно. Качество retrieval измеряют разными метриками; для нашей истории важнее всего одна — nDCG@10. Расшифровывается зловеще: normalized Discounted Cumulative Gain at 10, а по сути работает так:
- у каждого вопроса есть некоторое множество правильных документов в базе (их юристы-контрибьюторы заранее размечали);
- каждая RAG-конфигурация выдаёт первую десятку результатов;
- а nDCG@10 смотрит, сколько из них действительно правильные (соответствуют разметке) и на каких они позициях — потому что правильный документ на 1-м месте ценнее, чем на 10-м;
- чем ближе nDCG@10 к единице, тем лучше метод.
Среднее по 70 вопросам — это и есть оценка качества метода, которую я в этом посте всё время упоминаю.
Как это всё работает на практике. Допустим, вы сравнили два метода на этой выборке из 70 вопросов и получили, что у метода A средний nDCG@10 = 0.70, у метода B — 0.71. И кто лучше? 0.01, одна сотая разницы — это как-то подозрительно мало, да? Да, хоть и формально метод B лучше, но эта разница в 0.01 пункта может быть просто результатом того, что конкретно в эти 70 вопросов попали удачные для B и не очень удачные для A. Возьмите другие 70 вопросов — и разница может перевернуться, или исчезнуть, или сильно вырасти.
Чтобы понять, реальная ли это разница или шум, придумали статистические тесты, которые смотрят на две вещи:
- Насколько велика разница между средними значениями метрики у методов (тот самый 0.01)?
- Насколько по-разному эти методы ведут себя от вопроса к вопросу: бывает, что метод стабильно даёт nDCG где-то в районе 0.70, а бывает — на одних вопросах 0.30, на других 0.95. Чем стабильнее метод и больше разница между средними (тот самый 0.01) — тем легче поверить, что эффект настоящий.
И в этом месте слоном в комнате является количество ваших данных: чем меньше у вас выборка, тем более крупным должен быть эффект, чтобы тест признал его реальным. На 70 вопросах можно отловить только очень заметные различия. Мелкие — теряются в шуме, независимо от того, существуют ли они в реальности.
К этому добавляется ещё одна тонкость, важная для исследований, где сравниваются сразу несколько методов между собой. У меня их по сути шесть, и каждое попарное сравнение — это отдельный тест; всего получается несколько десятков тестов. И чем больше тестов вы делаете, тем выше вероятность, что хоть в одном из них «значимая» nDCG-разница объявится просто по случайности — даже если все ваши методы на самом деле одинаковые. Для неофитов статистические правила часто объясняются на выбрасывании кубика: если кинуть кубик три раза, получить удивительные последовательности сложно, а если кидать тридцать раз подряд — может получиться и подозрительно невероятная серия.
Чтобы такие случайные «открытия» отсеивать, статистики придумали поправки на множественные сравнения. Я использовала одну из самых распространённых — поправку Холма. Она поднимает планку доверия пропорционально количеству проведённых тестов, и в результате срезает те различия, которые «значимы» только из-за массовости тестирования, и оставляет только действительно воспроизводимые эффекты.
Сразу оговорюсь, что во всех этих изысканиях и объяснениях я полностью полагалась на нейросети. Мои личные мозги очень давно не работали настолько интенсивно, насколько они работали во время всей статистической части, для меня всё это непознанно и сложно. Во многом я пишу этот пост, чтобы окончательно объяснить самой себе, что пошло не так. Но одна из целей — попробовать задать тренд и культуру попыток добиваться статистической значимости в LegalTech-среде, а не плодить субъективные оценки или маркетинговые клеймы.
Если суммировать, статистическая значимость — это попытка отделить настоящие эффекты от шума, который неизбежно возникает при работе с ограниченной выборкой. Без неё любые «у нас на 30% лучше» — это замеры без прозрачной методологии, ничего не говорящие о том, повторится ли результат на других данных. С подтверждённой статистической значимостью у нас есть основание утверждать, что эффект устойчивый. Базовых инструментов, которыми её добиваются, ровно два: достаточный размер выборки и поправки на множественные сравнения, когда тестов несколько. Первое — про то, чтобы шум усреднился; второе — про то, чтобы случайные совпадения не выдали себя за открытия. И того, и другого хочется видеть больше, чем сейчас. Собрала ключевое в картинку:

Что из моих исследовательских вопросов удалось и не удалось проверить
После поправки Холма из 30 моих тестов значимым оказался один — Summary-Only против SAC. На этом всё. Остальные ключевые выводы — это тенденции, недоказанные различия или эффекты ниже порога наблюдения.
Вообще это не прям приговор, так как можно пытаться разграничить, где отсутствие значимости — это проблема выборки, а где это сам по себе содержательный вывод.
Реранкер не помогает? Между «без реранкера» и «с bge-реранкером» средние значения nDCG@10 различаются на тысячные доли — то есть на величину, сильно меньшую типичного разброса между вопросами. Контрольный прогон с другим реранкером (mmarco) дал ту же картину: тысячные доли, неотличимые от шума. Оба результата формально неотличимы от нуля. Это недостаточно, чтобы сказать, что реранкер не работает. Это означает, что на моих данных эффект, если он есть, меньше того, что эти данные позволяют засечь. Чтобы уверенно отличить прирост в 0.005 пункта от нуля, нужна выборка порядка 5000+ вопросов. У меня — 70.
Это всё равно полезная информация: как минимум, она означает, что готовый, из коробки взятый реранкер не даёт очевидно бросающегося в глаза прироста на legal-RU-задаче. Но и смело утверждать, что реранкер на юридических текстах бесполезен, я на своих 70 вопросах не могу.
Managed vs custom — разницы нет? Разница между качеством retrieval у Google File Search и своего custom-пайплайна — 0.007 пункта. Тоже сильно ниже порога наблюдения. Вывод аналогичный: разница может быть есть, может быть нет, но мои данные однозначно этот вопрос не закрывают.
BM25 всё ещё ого-го-го? Поиск по ключевым словам, придуманный задолго до векторных эмбеддингов, отстал от лидера на 0.08 — то есть совсем немного. С одной стороны, это может быть реальное свойство компактного, тематически кластерного корпуса: 218 документов в 10 блоках, лексические совпадения довольно специфичны. С другой — это тоже может быть артефактом маленькой выборки: возможно, в моих конкретных 70 вопросах случайно оказалось много таких, с которыми лексический поиск справляется. На большом корпусе, где типовая лексика судебных актов становится менее специфичной, отставание BM25 почти наверняка вырастет. Но это тоже предположение, не доказанный факт.
Если честно подытожить, главный неудобный вывод первой части такой: из всех красивых сравнительных историй, которые мне хотелось рассказать, более или менее уверенно я могла бы рассказать об одной — Summary-Only значимо лучше SAC. Но и здесь оказалась своя ловушка, повергшая меня поначалу в сильное уныние.
Проблема номер два: дедупликация чанков (что?), или почему нельзя верить даже единственному статистически значимому результату
В большинстве legal RAG-систем retrieval работает с чанками — фрагментами текста фиксированной длины. Архитектурно системе ставится задача «верни top-20 чанков, больше всего похожих на вопрос». Но одно стандартное судебное решение на стандартном чанкинге по примерно 500 токенов — это десятки чанков (на моём корпусе получилось в среднем 39 чанков на решение).
При этом юрист-пользователь, особенно в сценарии поиска релевантной практики, не хочет чанки, он хочет конкретные дела. На каком-то этапе чанки надо склеить обратно в список документов: это называется дедупликацией. То есть взять список top-20 чанков с их уникальными doc_id, пройтись по этим id и собрать из них список документов. Потом по этому списку документов считаются метрики, в частности основная «сколько правильных дел в первой десятке» (nDCG@10).
Штука в том, что дедупликация срабатывает принципиально по-разному для разных методов. Если чанки одного дела лежат в векторном пространстве близко друг к другу, то top-20 чанков после склейки могут дать:
- 5–6 уникальных дел — оставшиеся 14–15 слотов занимают повторные чанки тех же дел;
- 20 разных дел, если каждое дело представлено одним эмбеддингом (как в Summary-Only);
- Одно единственное дело, если все top-20 чанков оказались из одного дела.
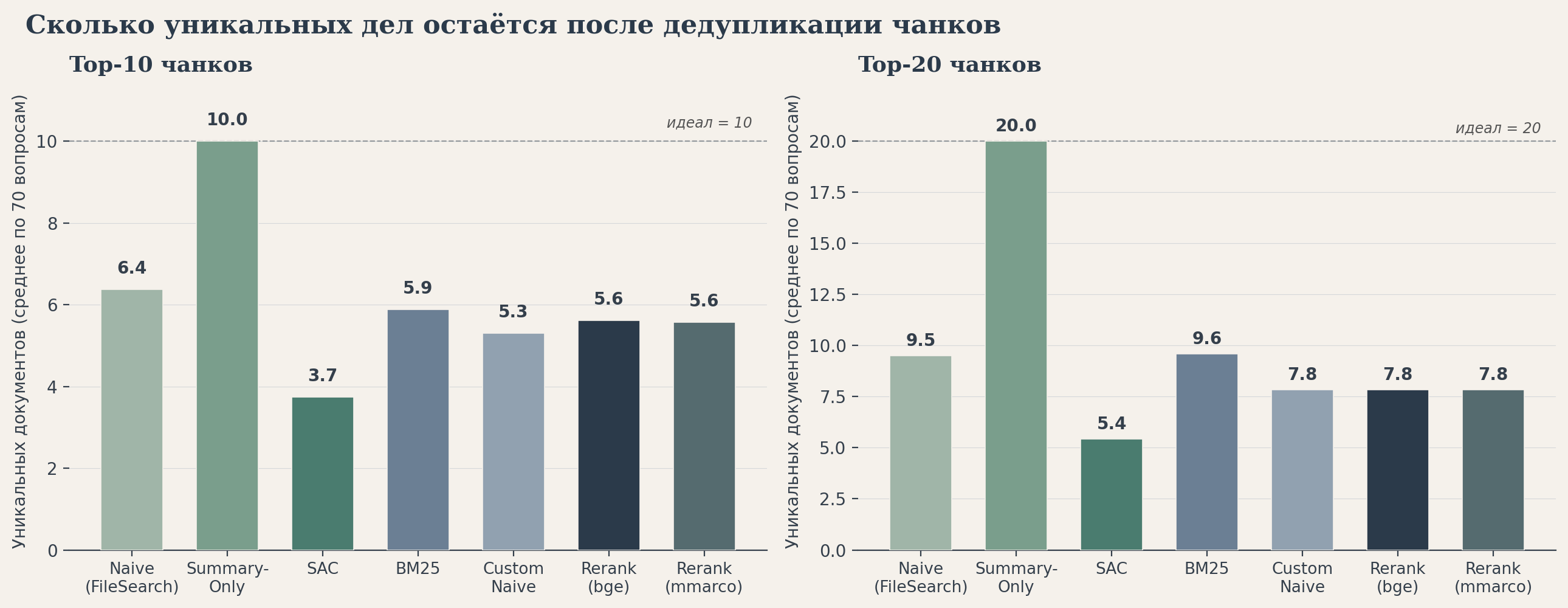
Смотрите на левую часть графика: это среднее число уникальных дел, остающихся после склейки первых 10 чанков выдачи. У Summary-Only ровно 10 — по дизайну метода: один документ всегда даёт один эмбеддинг, повторам взяться неоткуда. У большинства остальных методов — 5–6 уникальных дел, остальное в десятке — это повторные чанки тех же дел. У SAC меньше всего — 3.7 уникальных дел в среднем, то есть в десятке физически лежат чанки всего трёх-четырёх документов.
Собственно в чём главный факап? Метрика nDCG@10 спрашивает: «сколько правильных дел в первой десятке?». Summary-Only на этот вопрос отвечает, имея в десятке 10 разных дел и 10 шансов на попадание. SAC отвечает, имея 3–4 дела и, соответственно, 3–4 шанса. Это неравный старт — и значительная часть «преимущества» Summary-Only над SAC, которую я записывала на счёт качества retreival, на самом деле заложена в самой архитектуре сравнения.
По сути это значит, что сравнение двух методов при фиксированном top-20 просто нечестное, если один из них даёт 20 уникальных дел, а второй — 5–6. Методы, скорее всего, решают разные задачи. SAC может отлично справляться с точечным вопросом, где нужно одно конкретное дело поднять наверх — кластеризация чанков тут работает на нас. На обзорном же вопросе, где нужно собрать несколько источников, тот же механизм работает против: вверху стоят три дела вместо десяти. И это нужно было учесть при проработке методики, чего я не сделала, и пока не до конца придумала, как можно было бы сгладить этот эффект.
Привет, коллеги, занимающиеся legal RAG
Этот шаг — склейка чанков в дела — кажется, может оказаться несколько упущенным из внимания в реальных пайплайнах. Многие ли выходят за пределы фиксации top_k? Делает ли кто-то его динамичным, пока не наберётся достаточный список документов? При этом кажется, что для юриста-пользователя это именно та переменная, которая определяет, сколько разных дел он видит в аутпуте.
Если вы строите RAG-систему для поиска судебной практики, имеет смысл посмотреть, сколько уникальных дел в среднем получается в вашем top_k после дедупликации. Если вы это уже учитываете и продумали — обязательно расскажите, как именно.
Планы на будущее
Отчёт публиковать я, конечно, пока не буду, и в целом беру паузу, чтобы подумать, как дотянуть имеющиеся данные до состояния, где гипотезы действительно проверяются. Десять контрибьюторов дали мне 70 размеченных вопросов и 354 пары «вопрос × релевантный документ». Это было для меня бесплатно, но достаточно долго, с напоминаниями (это ни в коем случае не упрёк коллегам, а просто некоторая особенность организации работы с людьми, которую нужно учитывать). Собрать достаточную для статистически значимых результатов размеченную выборку — это либо совсем долго, либо очень дорого. Это вообще системная особенность практически любого гуманитарного домена.
Задачу эту я точно не брошу, во-первых, так как мне самой очень интересно докопаться до правды (даже если результатом будет отсутствие статистически значимой разницы). Во-вторых — чтобы работа коллег-контрибьюторов не пропала. Даже если моя вера в legal RAG угаснет (а она пока не гаснет!), данные всё равно можно по-разному использовать, как минимум, чтобы выложить открытый датасет для более подкованных в работе с данными специалистов.
Чтобы повысить шансы на какой-нибудь успех, предлагаю читателям, у которых есть своя рабочая подборка судебных актов, поучаствовать в сборе данных и разметке. Прикладываю сюда гайд для контрибьюторов, который я использовала в этом исследовании. Даже 200–300 вопросов от разных авторов позволили бы проводить исследования совсем другой надёжности.
Также я не могу не выжать хоть какую-то пользу из этого опыта, поэтому в обозримое время выдам смежные материалы. Первый — подробный обзор-мануал Google File Search: инструмент managed RAG, который, как мне кажется, совсем небесполезен, и во многом проще, чем самосборный RAG. Второй — обзор американского опыта исследований retrieval на судебной практике: там такие массивы данных, о которых мы можем только мечтать, но точно можно что-то почерпнуть для методологии.
Заходить на принципиально новую для себя поляну (это что-то близкое к ML уже) как будто стало сильно легче, чем было, благодаря вайб-кодингу и нейросетям. Но и постыдно облажаться благодаря им же тоже довольно просто. Во мне сильно боролись перфекционизм и стремление выдать уверенный и качественный результат с сожалением о потраченных усилиях и внутренним дедлайном под конец апреля, когда я хотела опубликовать отчёт об эксперименте. В итоге перфекционизм победил и получился этот пост: надеюсь, он другим aspiring-ресерчерам, недавним или всё-ещё-юристам, поможет не пройтись по тем же граблям.