Document-Level Retrieval Mismatch: ищем иголку в стоге плоских чанков
Обзор статьи о простом в реализации способе организовать RAG, а именно добавлении саммери текстов в качестве метаданных к чанку. А также о проблеме, которую этот способ эффективно решает, ставшей метрикой качестве RAG-систем.

Предлагаю сегодня почитать интересную и совсем свежую статью от группы исследователей из европейских университетов Towards Reliable Retrieval in RAG Systems for Large Legal Datasets, затравку для которой я давала в своей первой публикации из цикла Rise of RAG. Написана статья, что примечательно, на грант Евросоюза, а еще говорят, что в Европе душат развитие ИИ! Но шутки в сторону, предлагаю обсудить эту работу с двух основных ракурсов: какую проблему RAG-систем коллеги описывали и какой элегантный способ её решения предложили.
Особенности юридических текстов
Мне понравилась эта статья тем, что авторы довольно удачно и более или менее исчерпывающе суммировали особенности самых разных юридических текстов (а не только нормативных правовых актов, на которых в основном был фокус в первой публикации). В чем мы, коллеги-юристы, грешны (и для обстоятельной работы с Deus Machina вынуждены эти грехи как-то теперь исправлять):
- То, что авторы называют Lexical Redundancy, имея в виду однообразие и шаблонность юридических формулировок. Для юридических текстов характерна стандартизированность (а часто и «бюрократизированность» в худшем смысле) ((привет адептам лигал дизайна!)). В массиве документов, например договоров одного и того же типа, мы видим одни и те же шаблонные формулировки, повторяющуюся структуру, иной раз отличаются разве что названия сторон или даты. К таким массивам плохо применим поиск по косинусному сходству, у системы не получается локализовать уникальные фрагменты, она легко путается и выдает не тот документ.
- Юридические тексты обычно имеют сложную структуру с разделами, подразделами и многочисленными перекрестными ссылками. Как обсуждали и в первой публикации, стандартные способы нарезки текста (далее чанкинг или чанкование) этого не учитывают, и возвращаемый системой чанк может быть семантически релевантен, но потерять смысл без окружающего контекста.
- На юридические вопросы часто невозможно ответить, оперируя только одной частью документа — нужная информация бывает разбросана по нескольким разделам или даже разным документам. Это усложняется еще и практикой введения терминов и определений (иногда отдельным разделом, иногда прямо в тексте). Для корректного ответа требуется интеграция рассредоточенных фактов, а стандартные методы чанкинга не обеспечивают такую связь.
- Для нас критично, чтобы найденный системой чанк происходил из конкретного документа, нам не нужны правильные по сути цитаты, извлечённые из похожего, но ошибочного документа. Мы ожидаем прозрачной цепочки рассуждения, обеспечивающей traceability — возможности отследить путь от ответа к источнику (за это юристы так любят Notebook LM и Perplexity).
Все эти особенности не очень хорошо сочетаются со стандартными методами чанкинга. Авторы не используют в статье термин «flat RAG», но имеют в виду как раз плоские (в смысле одноуровневости документов) и наивно структурированные (по методу чанкования) базы знаний.
Наивное структурирование (например, разделение по длине чанка) разрушает логические единицы текста, делает фрагменты неполными с точки зрения смысла. А попытки превращать один документ в один большой чанк ухудшают само качество поиска. Авторы упоминают о продвинутых техниках чанкования (не будем останавливаться на них здесь, так как я о них буду писать отдельно), но говорят, что они слишком ресурсозатратны и не всегда учитывают перечисленные выше особенности юридических текстов.
Этот mismatch между особенностями юридических текстов и наивным чанкингом приводит к критичной проблеме использования эмбеддинговой RAG-технологии в юридическом домене. Авторы дали ей название Document-Level Retrieval Mismatch (далее DRM), которое можно приблизительно перевести как «ошибка выбора источника при извлечении».
DRM как проблема и как метрика
Собственно суть DRM как проблемы как раз в том, что RAG-система находит семантически близкий чанк в массиве документов — но не в нужном документе, не в том источнике, который требуется для ответа на запрос. Потеря связи чанка с исходным полным документом на этапе векторизации — фундаментальная причина DRM: ретривер возвращает не те документы, руководствуясь поверхностными семантическими совпадениями текста.
Мне очень понравилось, что авторы превратили проблему в оружие и стали смотреть на DRM как на метрику качества извлечения в RAG-системах. То есть считая DRM, авторы определяют долю от top-k (то есть лучших кандидатных) чанков, извлечённых системой, которые не принадлежат правильному («ground truth») документу. То есть если система выбирает из множества кандидатов только 5 лучших (top-5), DRM показывает, сколько из этих 5 — не из правильного документа.
Помимо DRM авторы статьи также применяли и привычные метрики Precision и Recall. Привычные для ML-специалистов, конечно, для нас это повод разобраться раз и навсегда, что же они значат.
I - Precision (точность) измеряет, какая доля текста, возвращённого системой на запрос, действительно относится к ground truth ответу. То есть это доля релевантных символов (или фрагментов) среди всех найденных системой.
Perplexity помогла с доступным сравнением: представьте, что вы собираете доказательства для суда и пошли в архив. У вас будет максимальная точность, если вы вынесли из архива только те документы, которые действительно пригодятся для дела и не взяли совсем ничего лишнего (соответственно, высокая точность — если релевантная большая часть, и немного лишнего).
Применительно к RAG-системам это работает так, что если система вернула много текста, но только небольшая часть этого текста действительно отвечает на вопрос, то Precision будет низким (а чем он выше, тем лучше). Например, система вернула 500 символов, ground truth ответ составляет 100 символов, из которых только 80 присутствуют в результате поиска. Precision в таком случае будет считаться как отношение 80 к 500, то есть составит 16%.
II - Recall (полнота) показывает, какую долю всего ground truth текста система реально смогла найти и вернуть. В рамках той же метафоры с архивом и судом это то, насколько вы смогли собрать все реально важные документы для дела из всего архива. Даже если вы достали что-то лишнее, главное — чтобы весь действительно нужный комплект оказался у вас. Если в ground truth ответе содержится 100 символов, а система нашла 80 из них, recall будет 80%.
В исследовании все метрики считались на уровне символов (character-level). Более низкий DRM и высокие Precision/Recall — это хороший результат, свидетельствующий о том, что RAG-система не только находит текст в нужном документе, но и правильно вычленяет необходимый контекст. А что, собственно измеряли? Измеряли, насколько рабочим является простой и элегантный метод борьбы с DRM как проблемой, придуманный авторами, а именно метод контекстно-обогащенного чанкования или Summary Augmented Chunking (SAC).
Summary Augmented Chunking — всё элегантное просто
Основная идея SAC — при нарезке текста на чанки к каждому чанку добавлять краткое синтетическое резюме всего документа. Резюме создается с помощью LLM, содержит основной контекст, сущности, цели и ключевые темы, объем — примерно 150 символов. После этого само резюме добавляется ко всем чанкaм, и затем уже такие обогащенные чанки собираются в векторную базу.

Вот промпт, который авторы использовали для создания резюме:
You are an expert legal document summarizer. Summarize the following legal document text. Focus on extracting the most important entities, core purpose, and key legal topics. The summary must be concise, maximum {char_length} characters long, and optimized for providing context to smaller text chunks. Output only the summary text. {document_content}
Как видите, метод очень простой по сути и в реализации, и авторы описывают следующие его практические преимущества:
- Метод легко интегрируется в уже имеющиеся пайплайны чанкинга и индексации, так как SAC требует только добавления одного дополнительного шага генерации резюме с помощью LLM для каждого документа, не требуя изменений в существующих поисковых и генераторных компонентах RAG-системы.
- Метод не требует больших дополнительных вычислительных ресурсов, так как нужен всего один дополнительный вызов LLM на документ.
- SAC можно легко масштабировать и применять к большим и динамически обновляемым базам знаний.
- SAC работает с синтетическими саммари и не требует тонкой настройки под тип документа или дополнительных экспертных знаний, что снижает затраты на внедрение.
- Метод отлично совместим с разными типами пайплайнов — его можно использовать как с плоскими эмбеддингами, так и с разными гибридными архитектурами (авторы не пишут об этом прямо и даже противопоставляют методы, но, как мне кажется, SAC хорошо сработает и с корпусом иерархических RAG-систем), а также с различными типами векторных баз данных.
Иными словами, он не требует сложных архитектурных изменений и дёшев по сравнению с продвинутыми методами типа иерархических и графовых RAG. Но неужели правда работает? Мы не зря разбирали выше метрики, поэтому теперь обсудим экспериментальную часть.
Эксперименты проводились на LegalBench-RAG — специализированном бенчмарке для оценки retrieval-компоненты в юридических RAG-системах. Он состоит из четырех поднаборов: CUAD (Contract Understanding Atticus Dataset, разные типы контрактов), MAUD (Merger Agreement Understanding Dataset, слияния и поглощения) ContractNLI (соглашения о неразглашении), PrivacyQA (политики конфиденциальности мобильных приложений).
Что сравнивали:
- Базовый (flat) RAG со стандартным (наивным) чанкованием по 500 символов.
- SAC RAG, в рамках которого, кроме того, тестировались две стратегии генерации резюме: a) generic — универсальное резюме по общему простому промпту, который приводила выше; b) expert-guided — по промптам, составленным юристами специально для датасетов с NDA и политиками конфиденциальности. Эти промпты предлали LLM не просто сделать краткий пересказ документа, а акцентировать внимание на ключевых юридических аспектах, отличающих документ от других похожих. Эти резюме были четко структурированными и немного длиннее (до 300 символов).
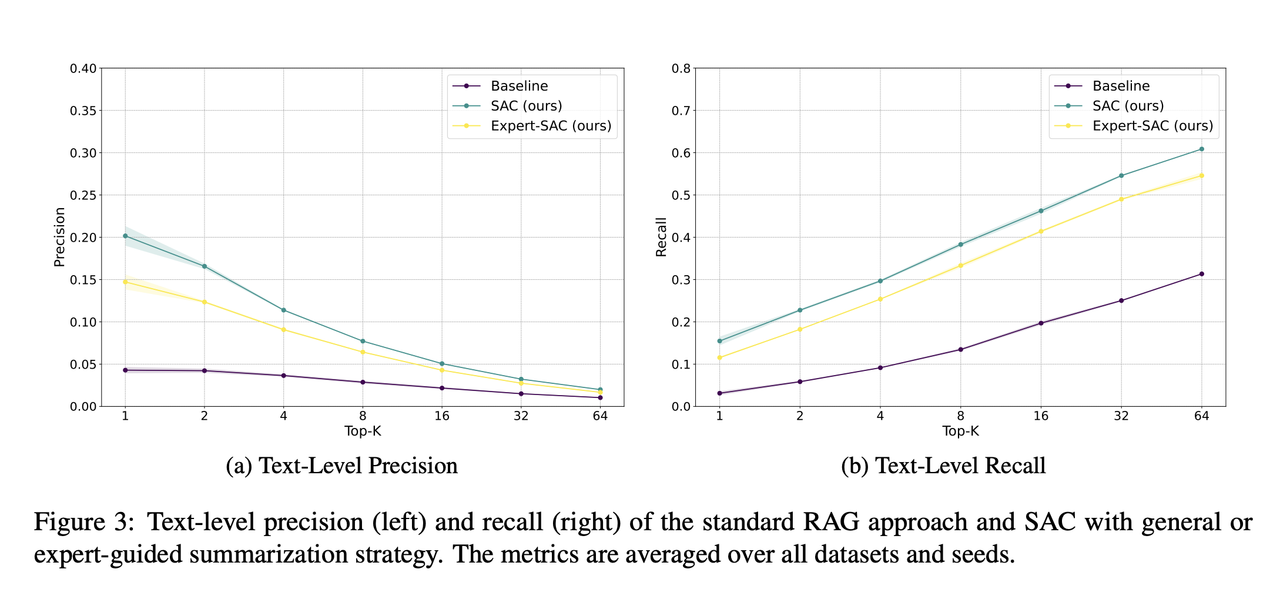
Что получилось — да что обещали, то и получили! DRM ниже примерно вдвое на всех датасетах, Precision увеличивается примерно на 30-40% (8% → 11%), Recall - также почти в два раза (22% → 42%).
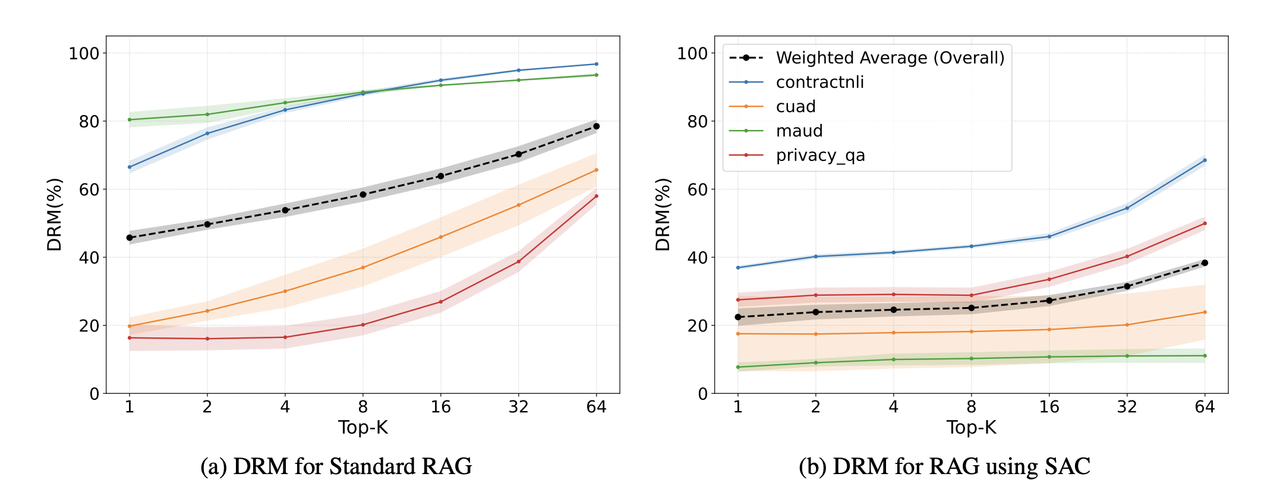
Примечательно, что generic резюме оказались эффективнее expert-guided. Авторы объясняют тем, что generic резюме более «чистые», и стандартным эмбеддинговым моделям легче соотносить их с самыми разными пользовательскими запросами. Впрочем, нужно учитывать ограничения эксперимента — использование только англоязычных документов контрактного типа, авторы также признают, что результат может быть другим на других эмбеддинговых моделях.
Выводы и методология
Область применения метода и use cases
1) Flat RAG не так уж и мёртв, его вполне можно оживить с помощью SAC для тех задач, где есть массив «одноуровневых» структурно похожих документов (договоров определенного типа, различных локальных актов и политик, односторонних документов типа оферт, стандартных условий и т.п.).
2) Flat RAG + SAC скорее не подойдет для задач, где критичен кросс-документный анализ (M&A и инвестиционное структурирование, исследования нормативного регулирования какой-то области и вообще работа с нормативными правовыми актами, антимонопольный комплаенс, сложные вопросы IP, где есть цепочки лицензий или производные РИД).
3) Метод хорошо может работать для задач по типу анализ типовых условий в массивах однотипных контрактов (например, для due diligence), поиск конкретных правовых позиций по отдельным вопросам в массиве судебной практики, анализ регуляторной отчетности (годовые отчеты, обязательное раскрытие информации эмитентов), работа с типовыми процессуальными документами по типовым для компании спорам, knowledge management в юридических департаментах и фирмах (анализ проектного опыта или работа с шаблонными документами), анализ закупочной документации.
Инфраструктура и экономика
1) SAC легко интегрируется в имеющиеся пайплайны с небольшими вычислительными затратами (впрочем, нужно ещё подумать, действительно ли они будут небольшими для баз знаний, состоящих из тысяч документов — вызов LLM для составления резюме и индексирования в векторную базу потребуется для каждого).
2) SAC комплементарен другим методам повышения качества поиска в RAG-системах по типу гибридного поиска (эмбеддинги+ключевые слова), реранкингом и query expansion — о них будет какая-то из следующих статей, не переключайтесь!
3) SAC вполне может быть применим к иерархическим системам, точнее корпусу, состоящему из нескольких MLR-деревьев, где резюме создается для каждого дерева. Возможно, я здесь слишком теоретизирую, но поводом развить дальше схемку из первой статьи не могу не воспользоваться:
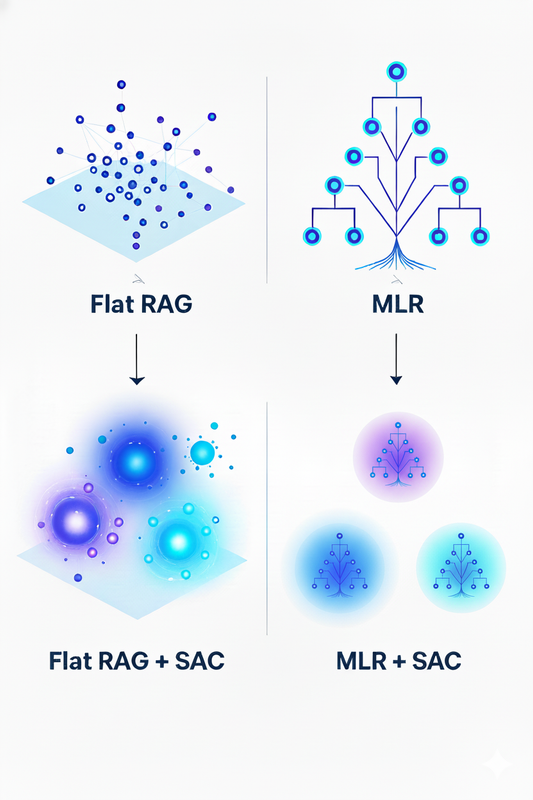
С графовым RAG мэтч, кажется, не так очевиден, поскольку построение «сообществ» как часть сути графового RAG уже будто инкапсулирует идею резюме. Хотя гипотетически эти резюме могут быть полезны до построения графа для улучшения качества определения сущностей, которые будут вершинами графа. Это, конечно, уже чисто теоретические, хотя и проверяемые, гипотезы.
4) DRM как метрика может быть очень понятно тем, кто рассуждает в бизнес-логике, и её можно позиционировать как ROI-метрику, показывающую, насколько сокращается время работы юриста по верификации того, что там нагородила нейросеть.
Архитектурная зрелость
1) SAC — метод простой по сути и в реализации, и может быть этаким quick win, заметно повышающим качество поиска. Но всё же он не идеален, как признают сами авторы, на 100% он не решает проблему DRM, а повышения Precision и Recall хоть и заметны в сравнении, но остаются не такими высокими в контексте конкретной задачи.
2) В какой-то момент нужно определять точку перехода к более сложным (MLR и графовым) архитектурам, задавая такие вопросы, как «когда связи между документами критичны для задачи?», «достаточно ли однороден корпус документов, имеет ли резюме вообще смысл?», «важны ли для задачи структурное и (или) темпоральное измерение?», «действительно ли этот метод дешевле, если в нашей базе тысячи документов?».
Напоследок немного личных впечатлений — почему-то мне было очень приятно прочитать эту статью. Мне понравился подход с превращением проблемы в метрику, и в этой метрике я вижу большой потенциал. Также не могла не думать о том, что я почти что интуитивно сама нащупала этот метод с резюме — эмбеддинги в моём боте сделаны именно из сгенерированных LLM пересказов сути дела с прямыми цитатами (хотя эти резюме совершенно точно можно назвать expert-guided). Только у меня получился не SAC, так как я ничего этими резюме не аугментировала, а просто summary chunk — сижу вот думаю, не сочинить ли мне по этому поводу тоже статью на arXiv и *зачеркнуто* получить грант.