Учимся взаимодействовать с новой сущностью: мой месяц в Claude Cowork
Рассказываю о своём опыте организации работы в Claude Cowork. Заглянем в агентский чёрный ящик, поделюсь своими рекомендациями по использованию Cowork.

В своей публикации про «агентский» RAG я заикнулась о том, что нам нужно формировать компетенции для контекстного инжиниринга, и буквально за пару дней стало ясно, что I don’t practice what I preach, когда я получила от почующего на лаврах Claude Cowork очень неудовлетворительные результаты по одной задаче.
Фрустрация, смутно напоминающая неофитское недовольство тем, что глупые нейросети придумывают судебную практику, жёстко замотивировала меня пойти и разобраться, как Коворк устроен. Поэтому добро пожаловать в этот пост, если хотите поучиться на чужих ошибках, понять, как там эти агенты бегают и как ими оптимальнее всего управлять (да, это требуется даже в таком приятном и максимально юзер-френдли интерфейсе).
Коворк стал главной темой сезона для тех, кому сложно разбираться с OpenClaw, смотивировал многих стать ✨клодобоярами✨ (то есть приобрести подписку за $100), потому что его возможности безусловно впечатляют. Некоторые умеющие заражать своим восторгом коллеги вложились в представление о Коворке как о революционной вещи, умеющей практически всё, чего мы так давно ждали от нейросетей, используя вайбкодинговые костыли (или собственный выгорающий мозг).
И вещь действительно революционная и во многом совершенно гениальная (особенно в элегантности подхода кодить, а не «элэлэмить» как можно больше всего)! Я пользуюсь им весь март, поручая всё больше и больше задач и получая много радости от результата. Но уже некоторое время я подозревала, что что-то я делаю не совсем так, и воооот в моей рабочей жизни случилась задача, показавшая масштаб этого «не так». Оговорюсь сразу, что пользование Коворком без заморочек годится для большинства задач, особенно подходящих под идеальные use cases. Но этой публикацией хочу вам показать, на каких задачах нужно заниматься грамотным контекстным менеджментом (и даже, не побоюсь этого словосочетания, контекстной архитектурой!) и контролем за агентами.
Задача была такая: покопаться в Excel-таблице на 60 строк, в каждой из которых по три объёмных юридических текста. Я хотела, чтобы агент заполнил в каждой строке с десяток ячеек с текстовыми комментариями о результатах смыслового сопоставления текстов друг с другом, а также некоторыми числовыми метриками, описывающими совпадения текстов между собой (accuracy, precision и recall, если кому интересно). После этого нужно было написать аналитический отчёт с диаграммками. Помимо таблицы, в папке было много всякого контекста — цели и задачи этого действа, правила написания комментариев, примеры предыдущей итерации.
Наверняка кто-то из вас уже заподозрил, что нельзя такие большие задачи вот так вываливать даже в гениальный Клод на клодобоярской подписке. Но мне казалось, что нуу у меня есть md-файл с инструкцией, задача расписана пошагово, так что всё будет нормально. Но, агрегируя отчёты, Клод сам заметил некоторые странные расхождения… и мы начали перепроверять. А потом ещё я сама стала замечать странное и задавать вопросы. И опять перепроверять. По ходу дела переписывать инструкцию. В том же чате, в том же Экселе.
На четвертой итерации, когда Клод обратил моё внимание на то, что пересчёт кардинально меняет результаты анализа, я поняла, что тянуть нельзя, надо разобраться, как мне по-нормальному организовать конкретно эту работу (она у меня будет регулярной), и как вообще организовывать подобную работу.
Предлагаю сначала заглянуть в этот агентский чёрный ящик, а потом вернуться к моему кейсу, понять, что с ним было не так, и как я планирую жить дальше. В конце — некоторые выстраданные методические рекомендации по использованию Коворка.
Что происходит внутри Cowork
Субагенты
Чат с Коворком, который видит пользователь, — это чат с оркестратором, который разбивает задачу на подзадачи и раздаёт субагентам. Если задача объемная, то субагентов несколько, и они работают параллельно, о чём пользователю гордо сообщается.
Параллельность — благо для скорости (можно, например, обработать 10 файлов параллельно за 4 минуты вместо 30), но и в определённом смысле ловушка, особенно когда нужен общий синхронизированный результат по задаче. Ловушка потому, что субагенты работают одновременно и при этом изолированно — каждый в своём контексте. Они не видят работу друг друга, у них нет общей памяти. Они могут скоординироваться, только если по результатам своей работы оставляют какой-то материальный след в виде файла в общей папке. Но не существует какого-то встроенного механизма их взаимной переклички в процессе параллельной работы.
Для задач, где каждый элемент независим, это вообще не проблема. Для задач с перекрёстными зависимостями, как в моём кейсе, это фундаментальная проблема.
О контексте и компактинге
Контекстное окно — это всё, что агент «держит в голове»: инструкции, история разговора, прочитанные файлы, результаты своих действий. Когда контекст заполняется до ~80–85%, система автоматически суммаризирует (компактит) историю. И это тоже вроде бы благо — больше нам не нужно самим отслеживать, когда контекстное окно прохудилось, делать ручную суммаризацию и открывать новый чат. Всё делается автоматически, разговор продолжается.
Но когда агенты что-то делают, да ещё и параллельно, контекст сжимается стремительно, компактинг происходит раньше, чем вы можете этого ожидать, и детали теряются: точные числа, конкретные формулировки инструкций, всякие другие нюансы. Агенты продолжают уверенно работать — но уже по пересказу своих же предыдущих шагов. Продолжают работать ...и снова тратить контекст, и компактинг срабатывает снова. И тогда суммаризируется уже суммаризированное. К третьему циклу — пересказ пересказа пересказа, возможно, похожий на исходные договорённости.
Один пользователь зарепортил случай, когда системный контекст (инструкции + описания подключённых сервисов) скушал 173K из 200K. Осталось 27K на работу. Получилось шесть компактингов за три с половиной минуты!!! на задаче «прочитай 4 файла и напиши markdown». А на Opus эта проблема мультиплицируется (и я заметила, что мне в Cowork гораздо больше нравятся результаты от Sonnet, чем от Opus).
Память
Если вы немного разбирались с агентами, то знаете об их свойстве — персистентности памяти. У Cowork два уровня персистентности:
1) глобальные инструкции загружаются в каждую сессию
2) память проектов — рабочих пространств с файлами, инструкциями и собственной памятью. Память между проектами изолирована. После каждого чата в проекте Claude сам решает, что стоит запомнить (названия файлов, паттерны ошибок, твои предпочтения, ключевые решения), и подгружает это в начало следующего чата в том же проекте и самостоятельно калибрует подходы (если в настройках включена memory).
Но внутри сессии память по-прежнему ограничена обычным контекстным окном и подчиняется тем же правилам компактинга. А отдельные сессии (без проекта) — вообще без памяти, каждая с нуля.
А ещё вы могли замечать, что сессии иногда просто исчезают. Не суммаризируются, не компактятся — просто пропадают. Может, Коворк помнит, что там было, а, может, и нет.
Что всё это значит на практике?
Что нужно создавать среду, устроенную по трём базовым принципам (дальше я их детализирую, но повторение здесь не лишне):
Это для кого-то может прозвучать как моё любимое осознание, что у велосипедов в среднем 2 колеса, и совершенно точно в Интернете кто-то об этом уже писал. И наверняка в ворохе гайдов по Cowork и агентам об этом всём уже есть. Но я из тех, кто тяжело воспринимает гайды, не попробовав инструмент руками. При этом я всё равно испытываю фрустрацию от неподготовленности, смешанную с детской восторженностью от копания в чем-то новом.
Кроме того, весь UX Коворка ну так дружелюбен пользователю, приятен глазу и вообще расслабляет. Разбивка на подзадачи, апдейты по статусам, красиво оформленный выходной файл. Окружающий хайп от коллег настраивает на максимальное доверие к инструменту. И для относительно простых задач — это всё честно и справедливо.
А для сложных и многосоставных этот UX работает как ловушка: нет индикаторов рассогласованности агентов и неуверенности оркестратора, нет автоматического sanity check.
Если сравнивать с OpenClaw, то более «голая» архитектура заставляет самостоятельно думать о памяти, контексте, передаче состояния. У пользователя просто нет других вариантов, потому что без этого ничего не заработает. Это сложно, но это очень продуктивно и по итогу не воспринимается как недостаток. Коворк это неудобство снимает — и вместе с ним снимает сигналы, которые помогают калибровать доверие к результату. Для Коворка в папке можно оставить полную свалку, а вот пример того, как рабочую папку следует организовать для толково работающего клешне-агента (спойлер: для сложных задач в Коворке нужно делать так же)
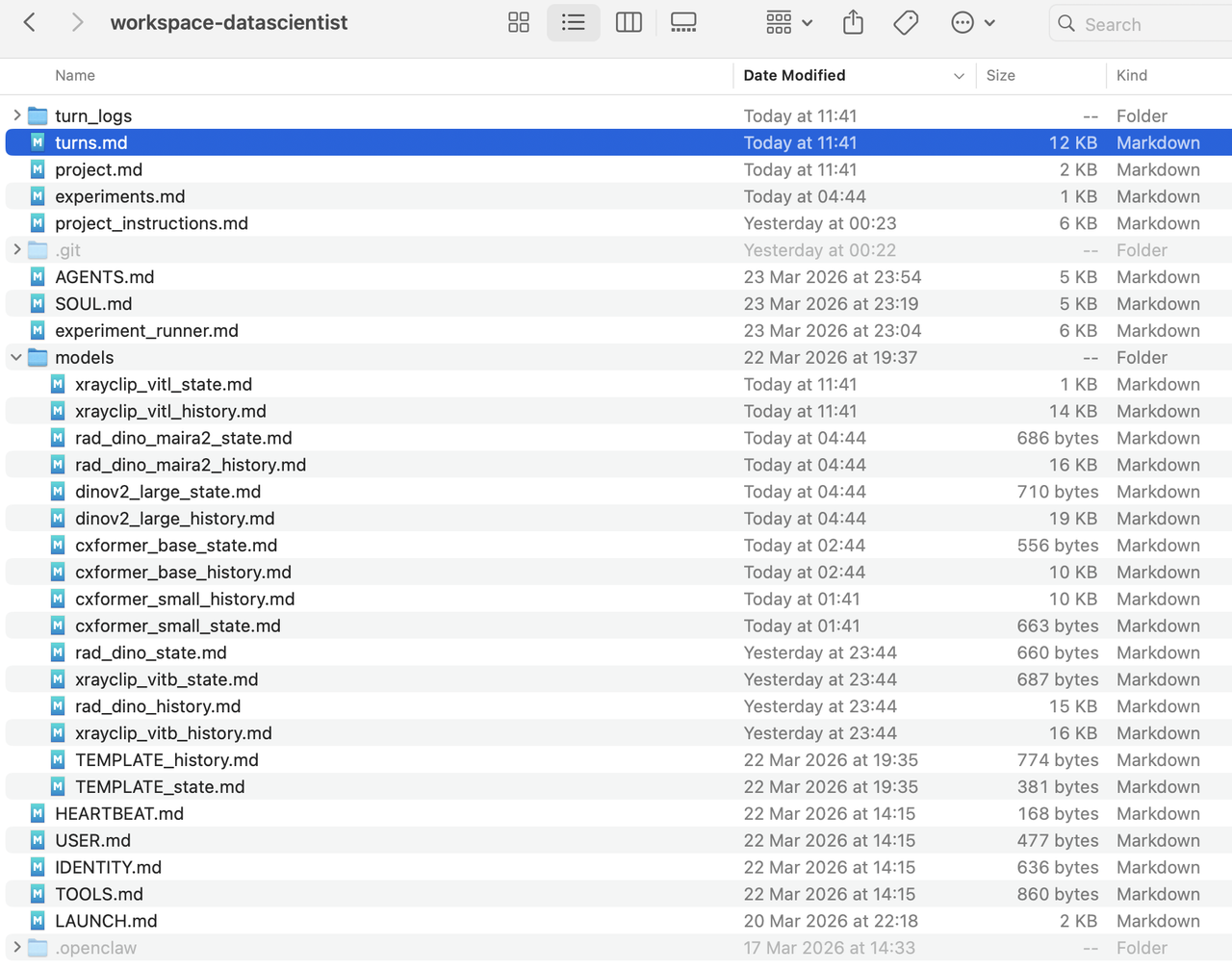
Эх, вот бы в гайдах от Anthropic, коих уже целая куча, появится материал, который бы честно разводил use-cases по уровню сложности и подсвечивал, где нужна архитектура процесса, т.к. дефолтные настройки не предназначены для этого… этот пост всё равно бы появился!) А если я ошиблась, и такой материал есть, скиньте мне, пожалуйста. От лирического предлагаю вернуться к практическому.
Что за ошибки я сделала, и как я постараюсь больше их не совершать
За 4 итерации перепроверок выявилось несколько типов ошибок:
— Агенты местами работали, нарушая методику проверки. И с высокой вероятностью потому, что у меня была одна большущая методика в одном файле на много разделов и строк. Из-за перегруженности контекста и компактинга некоторые нюансы методики где-то провалились в процессе.
— Тексты (комментарии о корреляции текстов между собой) и числа из метрик генерировались параллельно без сверки между собой, хотя кажется абсолютно логичным и самоочевидным сначала написать комментарий, а потом выставить по нему оценку (хочется передать привет Валентине Виноградовой и её легендарной фразе «Это параллельно последовательно»).
То есть оркестратор запустил параллельных агентов заполнять не строки последовательно, а столбцы параллельно… и да, при сложной задаче такие вещи лучше оговаривать. Это НЕ очевидно. Упрощенный пример, как это выглядело на деле: текст комментария «в заключении не указано на главное нарушение, найдено 2 нарушения из 3», а в числовой ячейке рядом указано «recall 100%» (хотя очевидно, что 2 из 3 не могут быть 100%). Таких случаев была почти половина, Карл!
— На этапе генерации аналитических отчётов тоже что-то пошло не так: агент, делавший отчет, просто посмотрел куда-то непонятно куда, но не в таблицу с расставленными оценками, и данные из отчета совершенно не коррелировали с данными в таблице.
Ни одна из этих ошибок — не галлюцинация в привычном смысле. Модель не выдумала факты, просто процесс работы агентов был организован совершенно провально. Из обсуждений ошибок с оркестратором стало ясно, как должно было всё быть сделано:
— Работу нужно было поделить на последовательные этапы, каждый в отдельном чате в Cowork— После каждого этапа нужен аудит проделанной работы— На каждый этап своя короткая четкая методика
То есть:
1) Пишем только текстовые комментарии, метрики не считаем →
2) Независимая верификация другими агентами — перечитывают полные тексты с нуля →
3) Один агент (для единого понимания методики) считает все метрики последовательно с аудит-трейлом (для каждой строки записывает промежуточный расчёт) →
4) Финальная проверка согласованности комментария и метрик →
5) Генерация отчёта. Длинный выдох.
При этом параллелизм остаётся, но только внутри этапов (разные батчи кейсов разным агентам). Между этапами — строгая последовательность с промежуточными файлами как точками контроля.
Когда Cowork работает и так, а когда нужна архитектура
Моя задача — не rocket science, но и нетривиальная. Но от стихийного grassroot восторга Коворком было ощущение, что он именно для такого и предназначен 🤓 и в целом да, но с определённой подготовкой. Но эта подготовка нужна не всегда, а для определённого типа задач, которые можно развести примерно так:

Если приводить какие-то юридические аналогии: проверка одного договора — первая категория. Due diligence по десяткам документов с перекрёстными ссылками, агрегированным скорингом и итоговым анализом — вторая.
Я много думала о том, что мы находимся в ситуации, примерно похожей на ту, что была год назад, когда далеко не все понимали, что промпты лучше писать определённым образом, а ещё отслеживать усталость контекста. В целом на мета-уровне работа с агентами осталось такой же (грамотно ставишь задачу и следишь за контекстным окном), но на более продвинутом уровне с усложнениями взаимодействия.
Сложность в том, что просто общаясь с моделью в чате, ты видишь каждый шаг, каждый следующий ход полностью зависит от тебя. Агенты меняют природу задачи: если ты не выстроишь процесс, то чёрный ящик и оркестратор выстроят его за тебя, а там уж как получится. Промпт-инжиниринг — это по сути лингвистическая задача, «как сказать, чтобы тебя максимально поняли». Работа с агентами — «как организовать процесс, чтобы ошибки не каскадировались», системно-архитектурная задача. И знаете, что мне это напоминает? Вайб-кодинг! И мою методичку.
До методички по агентам я, разумеется, ещё не созрела, но вот какие архитектурные правила уже понятны:

Сейчас я решаю одну похожую задачу, и вот как выглядит порционная работа агентов (батчи для контроля контекста, проходы = разделение по когнитивным задачам).
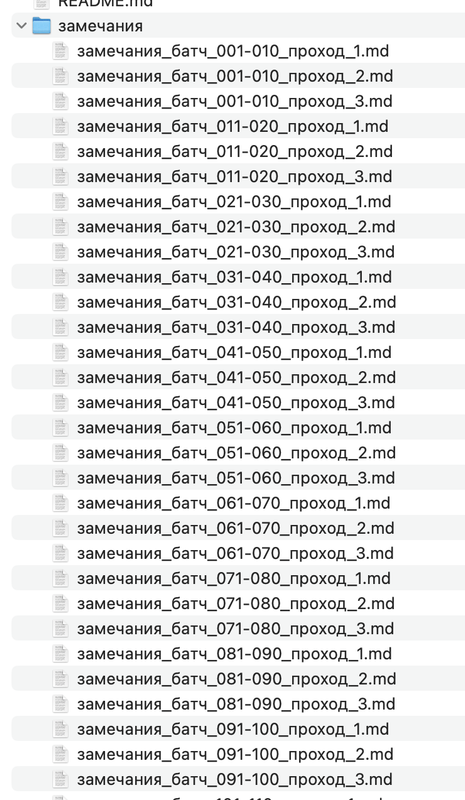
И ещё пара моих практических лайфкахов:
- Советуйтесь с Claude в чате, как вам правильно организовать работу по большой задаче. Как выстроить файловую структуру, нужен ли вам проект, что написать в инструкциях проекта, как оформить задачи для агентов на разные этапы, как синхронизировать аутпут между этапами для пунктов 2 и 4 из вышеперечисленных. Я же говорила, что напоминает методичку по вайб-кодингу…
- Придерживайтесь продуманных разработчиками use-cases, не относитесь как к волшебной палочке и единому окну в сказочный мир, когда ИИ работает, а вам платят зарплату. Коворк имеет специальный функционал, и многие задачи лучше по-прежнему решаются просто в чате (например, чтобы Коворк пошёл в Интернет — нужно еще постараться, то есть тоже эксплицитно на это промптить).
- Не пренебрегайте проектами, если даже ваши задачи можно решать параллельно, но они большие или просто разные. Надоест каждый раз писать инструкцию, будет обидно, если она исчезнет из памяти. Поймите чётко, когда точно хватит одного чата, а когда нужны проекты (как правило, для регулярных повторяющихся задач, ну и для многосоставных проектов с разными типами когнитивных задач).
В качестве еще одного комплимента OpenClaw отвешу, что все эти вещи проще делать, чем с Коворком, так как можно сделать себе ассистента, который возьмёт на себя всю эту рутину по декомпозиции задачи и последовательным запускам. 20 чатов в проекте — это целая куча кликов, и я пока не вижу, как это можно соптимизировать.
Cowork — прекрасный продукт, радикально упрощающий работу. Я наблюдала восторг и восхищение от него, но мне хочется донести, что яркое первое впечатление может сформировать определённую ментальную модель «делегируй и радуйся». И избыточное полагание на инструмент сможет отрикошетить, если начать пренебрегать проверками. В моём случае мне очень повезло: оркестратор сам споткнулся о неконсистентность, и мы начали ковырять эту кроличью нору, а ведь неправильные результаты могли бы каскадироваться дальше уже в абсолютно реальных процессах.
И несмотря на всё это, мне кажется, что происходит очень интересный сдвиг компетенций пользователей ИИ! Действительно, есть чему поучиться (и у Anthropic курс есть, кстати). Хотя, наверное, только мы научимся, как опять что-то новое захватит всеобщее внимание.